Етапи роботи
Навіть невеликий ML-проєкт потребує дисципліни в даних і метриках.
- аудит даних і формату
- підготовка навчальної вибірки
- навчання baseline-моделі
- оцінювання точності та помилок
- оптимізація inference
- інтеграція в інтерфейс
ML-проєкт починається з даних і критеріїв якості. Модель має не просто “працювати”, а бути вимірюваною: на яких прикладах помиляється, як часто, чому і чи достатньо цього для конкретного процесу.
У лабораторії ML розглядається як інженерний цикл: постановка задачі, підготовка датасету, базова модель, метрики, аналіз помилок, покращення і тестова інтеграція.
Такий підхід дозволяє швидко відрізнити реалістичну AI-задачу від задачі, де спочатку треба покращити дані або змінити процес.
Навіть невеликий ML-проєкт потребує дисципліни в даних і метриках.
Для різних задач потрібні різні метрики: accuracy, precision, recall, mAP, F1 або бізнес-метрики на кшталт часу, який система економить користувачу.
Для експериментів використовуються GPU-сервери, inference-сервери, Docker, Kubernetes та внутрішня обчислювальна інфраструктура лабораторії.
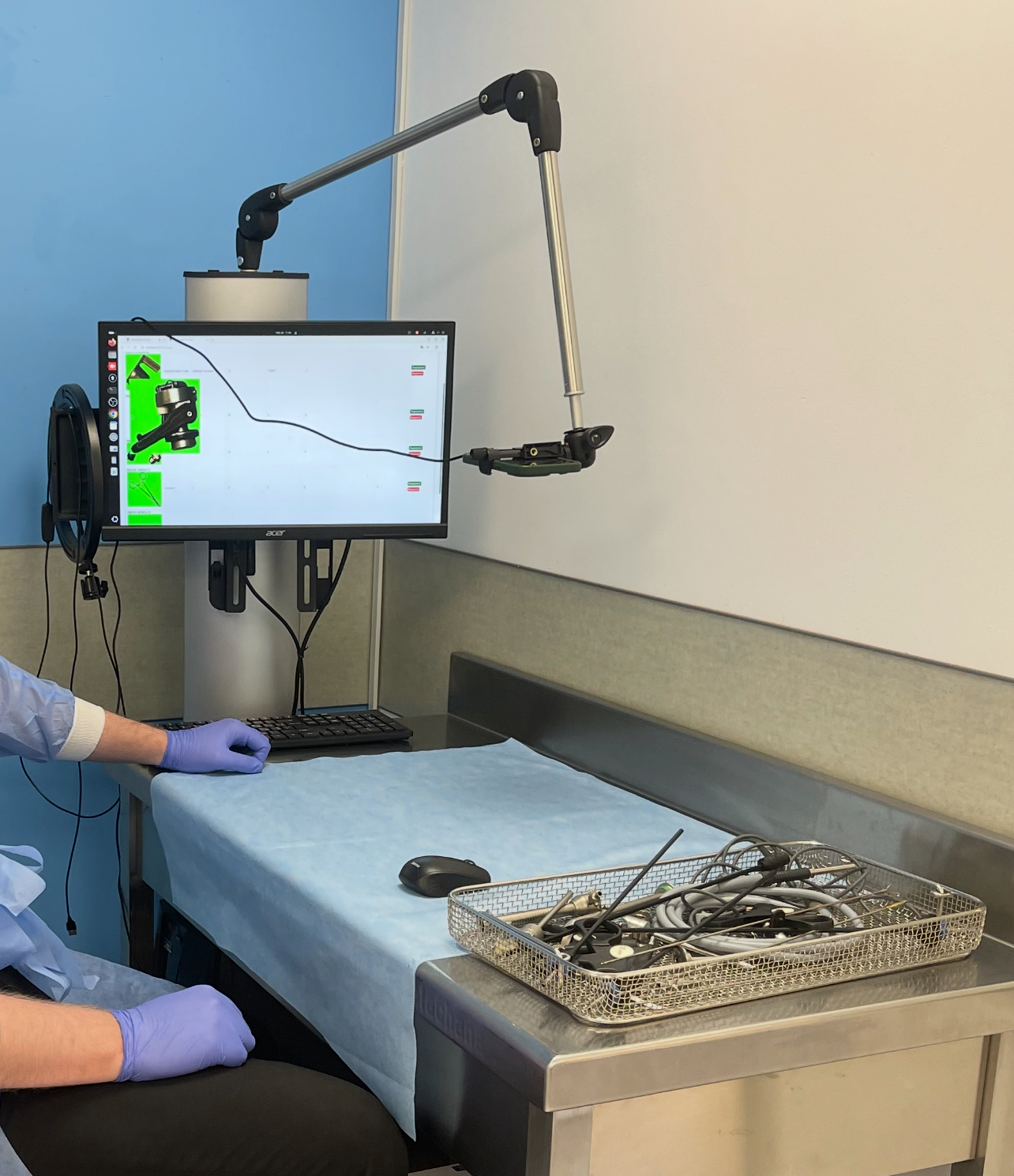 Дослідження Система розпізнавання хірургічних інструментів для Лікарні Святого Пантелеймона
Дослідження Система розпізнавання хірургічних інструментів для Лікарні Святого Пантелеймона Лабораторія дослідила та розробила комп’ютерну систему з камерою для розпізнавання, навчання і цифрового обліку тисяч хірургічних інструментів.
 Дослідження Інтелектуальний аналіз трафіку та заторів на дорожній інфраструктурі міста Львова
Дослідження Інтелектуальний аналіз трафіку та заторів на дорожній інфраструктурі міста Львова Дослідницький проєкт лабораторії спільно з Львівською міською радою для аналізу транспортних потоків, навантаження перехресть і причин заторів на вулицях Львова.
Іноді так, але якість залежить від задачі, різноманітності прикладів і вимог до точності. Часто малий датасет підходить для першого прототипу, але не для стабільного використання.
У прикладних задачах якість даних часто важливіша за вибір моделі. Погано описані або нерівномірні дані обмежують результат навіть для сильних алгоритмів.
Так. Зазвичай модель запускається як окремий inference-сервіс або API, а веб-додаток відповідає за користувацький сценарій, дані і перевірку результату.
Лабораторія готова обговорювати дослідження, прототипи та некомерційні проєкти з університетами, лабораторіями, компаніями, лікарнями й державними установами.