Work stages
Even a small ML project requires discipline in data and metrics.
- data and format audit
- training sample preparation
- baseline model training
- accuracy and error evaluation
- inference optimization
- interface integration
An ML project starts with data and quality criteria. A model should not just “work”; it should be measurable: where it fails, how often, why and whether that is enough for a concrete workflow.
In the laboratory, ML is treated as an engineering cycle: task framing, dataset preparation, baseline model, metrics, error analysis, improvement and test integration.
This approach quickly separates realistic AI tasks from tasks where data or the workflow must be improved first.
Even a small ML project requires discipline in data and metrics.
Different tasks require different metrics: accuracy, precision, recall, mAP, F1 or business metrics such as time saved for a user.
Experiments use GPU servers, inference servers, Docker, Kubernetes and the laboratory’s internal computing infrastructure.
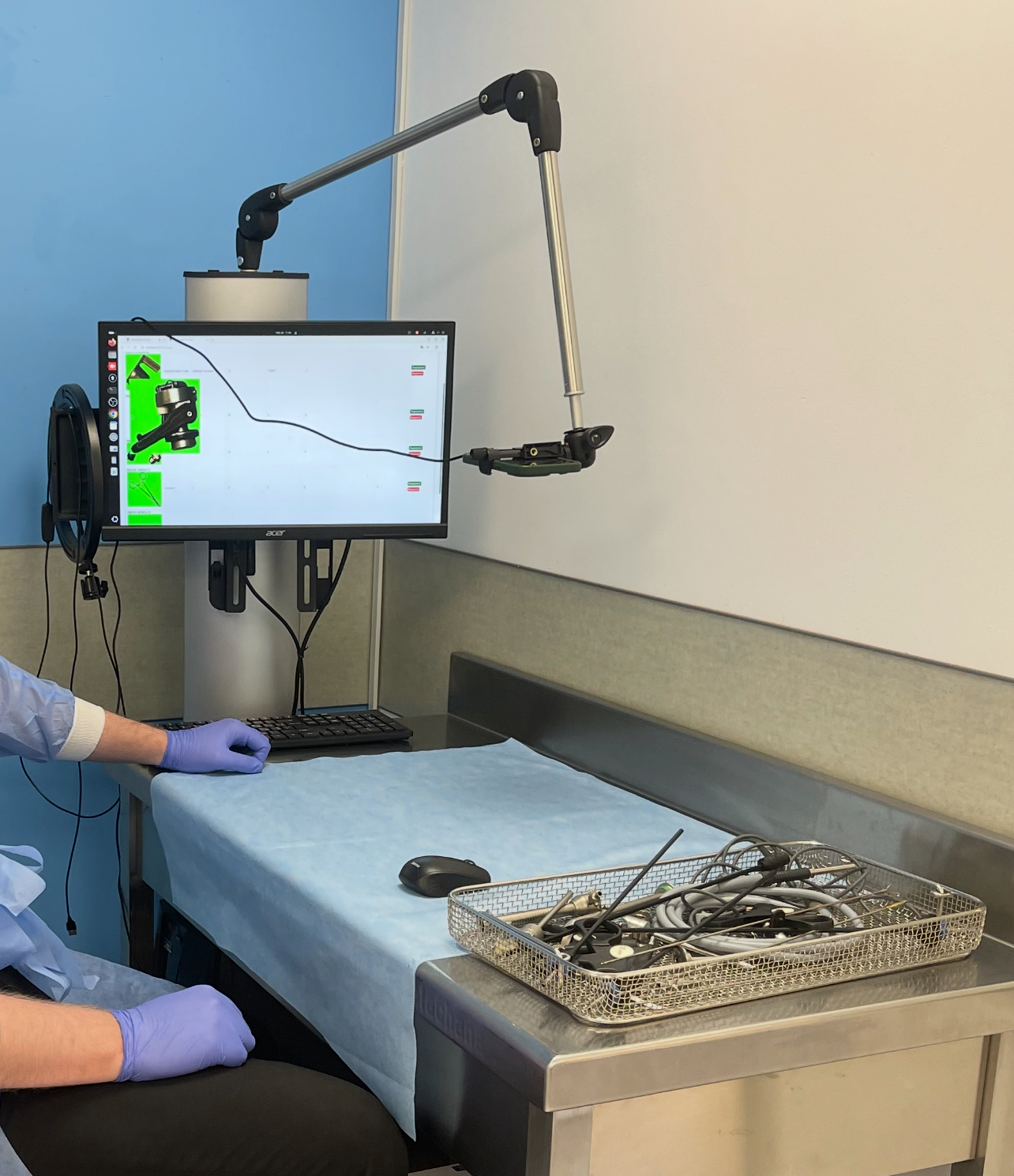 Research Surgical Instrument Recognition System for St. Panteleimon Hospital
Research Surgical Instrument Recognition System for St. Panteleimon Hospital The laboratory researched and developed a camera-based computer vision system for recognizing, training and digitally cataloguing thousands of surgical instruments.
 Research Intelligent Analysis of Traffic and Congestion on Lviv Road Infrastructure
Research Intelligent Analysis of Traffic and Congestion on Lviv Road Infrastructure A research project by the laboratory together with Lviv City Council for analysing traffic flows, intersection load and congestion factors on Lviv streets.
Sometimes yes, but quality depends on the task, sample diversity and accuracy requirements. A small dataset often fits a first prototype, but not stable use.
In applied tasks, data quality is often more important than model choice. Poorly described or uneven data limits results even for strong algorithms.
Yes. Usually the model runs as a separate inference service or API, while the web application handles the user workflow, data and result validation.
The laboratory is ready to discuss research, prototypes and non-commercial projects with universities, laboratories, companies, hospitals and public institutions.